A decade ago, assessing the condition of a road network required expensive specialist equipment, trained field engineers, and months of scheduled inspections. Today, a single dashcam the same type of device millions of drivers already use for insurance purposes combined with sophisticated artificial intelligence can do something previously unimaginable: extract over 70 distinct road condition parameters from a single continuous video feed, in real time, at the speed of ordinary traffic.
This is not a concept under laboratory development. It is a technology actively deployed by city governments, national highway agencies, logistics companies, and infrastructure analytics firms across the world. Every kilometer driven with an AI-enabled dashcam becomes a detailed diagnostic report on road quality, hazard presence, signage integrity, lane condition, and dozens of other parameters that engineers use to prioritize maintenance and allocate budgets.
The implications are profound. Road networks that once required years between comprehensive inspections can now be monitored continuously. A city bus, a delivery van, or a municipal maintenance vehicle becomes a rolling inspection unit every time it leaves the depot.
This blog breaks down exactly how AI achieves this feat what the 70+ parameters are, the computer vision and machine learning techniques that extract them, and why this technology is rapidly becoming the backbone of modern road asset management.
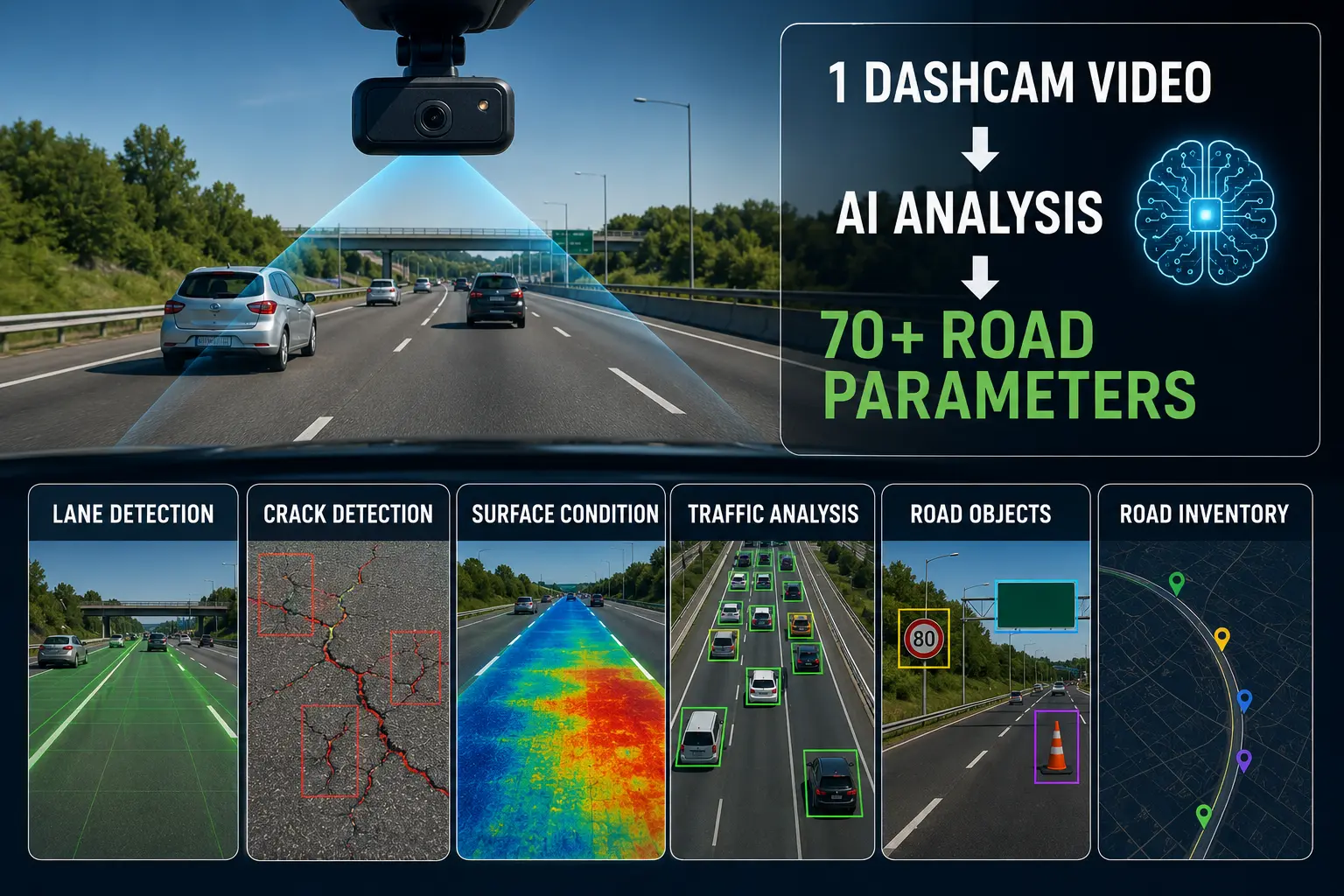
The phrase "70+ parameters" might sound like marketing language, but it reflects the genuine breadth of information that modern AI systems can extract from video footage. These parameters span multiple categories of road infrastructure and surface condition, each providing actionable intelligence for maintenance planning.
Here is a breakdown of the major parameter categories:
Each of these parameters is geo-tagged with precise GPS coordinates, timestamped, and stored in a structured database that integrates with road asset management platforms.
Extracting this volume of information from video requires a multi-layered AI technology stack. No single algorithm does everything instead, several specialized machine learning and computer vision systems work in parallel, each expert in its domain.
The foundation of pavement condition analysis is the convolutional neural network. CNNs are deep learning architectures specifically designed to process visual information by recognizing spatial patterns across image regions.
For road analysis, CNNs are trained on datasets containing hundreds of thousands of labeled road images frames annotated by human experts who have classified every visible defect, marking, and feature. A well-trained CNN learns to recognize cracking patterns, surface texture changes, and defect geometries across wildly varying conditions: wet roads, night footage, shadows, dirty camera lenses, and different pavement types.
Modern road analysis systems use ensemble CNN architectures, where multiple models specialized in different defect types cracks, potholes, markings, signs process each frame simultaneously. Their outputs are then aggregated by a fusion layer that produces a comprehensive condition assessment for every road segment.
While object detection locates specific features (a pothole here, a sign there), semantic segmentation goes further: it classifies every single pixel in a video frame. This allows the AI to understand the full spatial context of the road precisely mapping the carriageway, shoulder, lane markings, kerbs, footpaths, and adjacent structures as distinct zones.
Semantic segmentation enables accurate measurement of road width, shoulder extent, and marking coverage ratios parameters that pure object detection cannot reliably extract. It also helps the system distinguish genuine pavement distress from visual noise such as oil stains, painted road markings, or shadows that could be misclassified as cracks.
For identifying discrete objects traffic signs, guardrails, delineators, debris, road furniture AI systems use real-time object detection architectures such as YOLO (You Only Look Once) variants and Vision Transformer models. These systems can process video frames at 30+ frames per second, identifying and classifying dozens of object categories simultaneously within each frame.
When a dashcam video stream passes through an object detection pipeline, every traffic sign encountered is identified, its category classified (stop sign, speed limit, warning sign), its GPS location recorded, and its visual condition scored all within milliseconds.
One limitation of standard monocular dashcam footage is that it captures a flat 2D image of a 3D world. Extracting depth-dependent measurements pothole depth, rutting severity, shoulder width requires recovering three-dimensional information from the footage.
Modern AI systems achieve this through monocular depth estimation networks, trained to infer depth information from visual cues such as perspective, texture gradients, and scene geometry. Some systems use stereo dashcams with two lenses to compute true stereoscopic depth maps. Others fuse dashcam data with GPS-derived vehicle motion to reconstruct approximate 3D road geometry through structure-from-motion techniques.
Roads are not static in video the scene changes continuously as the vehicle moves. AI systems exploit this temporal information to improve detection reliability. A crack visible in three consecutive frames at the expected geometric progression of a road surface defect carries far higher confidence than a single-frame detection that could be a lens artifact or road marking.
Recurrent neural networks (RNNs) and attention mechanisms in transformer architectures allow the system to maintain context across frames, tracking features as they enter and leave the camera's field of view and correlating detections across time to produce stable, confident condition assessments.
Dashcams alone capture visual data, but road analysis AI integrates multiple data streams simultaneously. Inertial measurement units (IMUs) embedded in modern dashcam devices detect vertical acceleration events the jolts and vibrations associated with potholes, rough pavement, and surface irregularities that correlate with visual defect detections to improve confidence and enable detection of subsurface roughness not always visible on camera.
GPS data provides the geographic backbone, linking every detected parameter to a precise location on the road network. When combined with digital road network maps, the system can automatically assign detections to specific road segments, asset registers, and administrative boundaries enabling seamless integration with municipal GIS systems.
Understanding the end-to-end pipeline clarifies how raw dashcam footage becomes structured infrastructure data.
Step 1 — Video Capture: A dashcam mounted on a standard vehicle records video at 1080p or higher resolution while the vehicle operates normally.
Step 2 — Edge Processing or Cloud Upload: Depending on the system architecture, AI inference runs either on an onboard edge computing unit in the vehicle (enabling real-time alerts) or the footage is uploaded to cloud servers at the end of each trip for batch processing.
Step 3 — Frame Extraction and Pre-processing: Video is decomposed into individual frames. Image pre-processing algorithms correct for lens distortion, normalize brightness, and flag low-quality frames caused by rain on the lens, extreme glare, or camera occlusion.
Step 4 — Multi-Model Parallel Inference: The cleaned frame stream passes through multiple specialized AI models simultaneously — surface defect detectors, marking analyzers, sign classifiers, depth estimators each contributing their outputs to a unified data structure for each frame.
Step 5 — Geo-tagging and Segment Aggregation: Detections are matched to GPS coordinates and aggregated into road segments of defined length (typically 10–100 meters). Individual frame-level detections are statistically consolidated into segment-level condition scores.
Step 6 — Quality Assurance and Anomaly Flagging: Automated quality checks filter spurious detections, flag low-confidence outputs for human review, and verify spatial consistency of reported features.
Step 7 — Dashboard Visualization and Work Order Generation: Processed data populates road asset management dashboards, displaying condition heat maps, prioritized maintenance lists, before/after comparison views, and budget optimization recommendations.
The entire pipeline from dashcam footage to actionable maintenance intelligence can be completed within hours of data capture for batch processing systems, or in real time for edge-enabled platforms.
Forward-thinking municipalities are retrofitting existing city vehicle fleets buses, garbage trucks, street sweepers with AI dashcams. These vehicles collectively cover the entire road network multiple times per week as part of their normal operations. The result is effectively continuous road monitoring at near-zero marginal cost beyond the dashcam hardware and software subscription.
Highway agencies are using AI dashcam systems to replace or supplement traditional pavement condition survey vehicles that cost several hundred thousand dollars each and can only survey at reduced speeds. Standard vehicles equipped with AI dashcams survey at traffic speed, covering far more network length per day and at a fraction of the cost.
Large logistics companies with thousands of vehicles have found that AI dashcam road data serves a dual purpose: improving road condition intelligence for route planning while simultaneously generating a commercially valuable dataset on network condition that transportation agencies are willing to purchase.
A legitimate question is how accurately AI dashcam systems perform compared to traditional ground truth inspection methods.
Independent validation studies comparing AI dashcam outputs against manual inspection and dedicated pavement condition measurement vehicles show that leading systems achieve crack detection accuracy rates above 85–92%, pothole detection rates above 90% under clear daylight conditions, and sign condition classification accuracy above 88%.
Accuracy drops under adverse conditions nighttime footage without adequate lighting, heavy rain, and snow cover all reduce performance. Most systems include data quality scoring that flags low-confidence assessments collected under poor conditions, prompting re-survey when conditions improve.
The combination of high spatial coverage and reasonable accuracy makes AI dashcam data extremely valuable for network-level maintenance planning even where individual detection confidence is imperfect patterns across thousands of detections are statistically robust even when individual assessments carry uncertainty.
Despite remarkable capabilities, AI dashcam road analysis faces real-world limitations that engineers and policymakers must understand.
Data standardization remains a challenge. Different AI platforms output road condition data in varying formats, making it difficult for agencies working with multiple vendors to consolidate data into unified management systems. Industry standardization efforts are underway but incomplete.
Edge case performance unusual road configurations, non-standard signage, regional pavement types unfamiliar to training datasets can reduce model accuracy in specific geographic contexts, requiring local model fine-tuning.
Privacy considerations arise when dashcam footage captures pedestrians and vehicle license plates. Leading platforms apply automatic anonymization blurring faces and plates before data processing and storage, but regulatory requirements vary by jurisdiction and must be carefully navigated.
Data volume management is a practical engineering challenge. A fleet of 100 vehicles generating continuous 1080p footage produces petabytes of raw data per year. Efficient edge inference, intelligent frame sampling, and compressed output formats are essential to making large-scale deployment economically viable.
The trajectory of AI dashcam technology points toward a near future where continuously updated digital twins of entire road networks become practical. A digital road twin is a living virtual replica of a road network, updated in near real time by data from multiple sources dashcams, IoT sensors, satellite imagery, weather stations and used to simulate future deterioration, model the impact of maintenance interventions, and optimize budget allocation across thousands of road segments simultaneously.
Emerging developments to watch include multimodal AI models that jointly process video, LiDAR, and radar data from sensor-fused dashcam units; foundation models trained on massive multi-country road datasets that generalize accurately across diverse pavement types and climates; and automated maintenance dispatching where AI dashcam alerts trigger direct work order creation and crew scheduling without human intermediary steps.
As dashcam hardware costs continue to fall and AI model performance continues to improve, the economic case for universal AI road monitoring becomes compelling even for road networks in lower-income regions where infrastructure funding is most constrained.
The ability of AI to analyze 70+ road parameters from a single dashcam video represents one of the most practical and immediately impactful applications of artificial intelligence in civil infrastructure. It takes something already present in millions of vehicles a camera and transforms it into a precision diagnostic instrument capable of providing insight that previously required expensive specialist equipment and years of planning.
For road agencies, the technology dramatically lowers the cost and increases the frequency of pavement condition data, enabling genuinely proactive maintenance planning. For cities, it offers a path to continuous road monitoring using existing fleet vehicles at minimal additional cost. For taxpayers, it means roads maintained more intelligently — with budgets directed toward sections that need treatment most urgently, before expensive failure occurs.
The road network is one of the most critical and most underfunded categories of public infrastructure worldwide. AI-powered dashcam analysis will not solve every infrastructure challenge, but it gives decision-makers something they have long lacked: comprehensive, current, and continuously updated knowledge of exactly what condition their roads are in — and where to act first.
Book a demo with RoadVision AI to experience the future of intelligent road surveying
Some AI platforms are designed to work with standard consumer-grade dashcams already installed in vehicles, using cloud-based AI processing to analyze the footage. However, higher-accuracy systems typically use purpose-built dashcams with better image sensors, wider dynamic range for challenging lighting conditions, built-in IMUs for vibration data, and edge computing chips for onboard inference. The trade-off between cost and accuracy depends on the application.
This varies by platform maturity and road conditions. Leading systems credibly detect 60–80+ parameters with varying levels of confidence across different conditions. Pavement defect categories, lane markings, and traffic signs typically have the highest accuracy. Parameters requiring precise dimensional measurement pothole depth, crack width — are generally less accurate than detection-only parameters but continue to improve as depth estimation AI advances.
AI dashcam surveys typically cost 5–20 times less per kilometer than dedicated pavement condition measurement vehicle surveys, depending on the system, fleet size, and data processing model. The primary cost advantage comes from the ability to use existing fleet vehicles rather than specialized survey equipment, and from surveying at normal traffic speeds rather than reduced survey speeds.
For network-level planning purposes, quarterly or semi-annual surveys are typically sufficient. For high-traffic urban networks or roads in areas with severe winter weather, monthly surveys may be warranted to detect rapid deterioration. The low cost of AI dashcam surveys makes higher-frequency monitoring economically practical in a way that traditional methods never were.

The Autonomous Road Engineer
AI that is transforming road infrastructure, from reactive to predictive.


.webp)